Le RAG : Retrieval Augmented Generation, c'est quoi ?
Le RAG est une technique d’IA qui combine la récupération de données et la génération de texte pour apporter des réponses fondées sur des sources fiables et traçables. Pour faire simple, c’est comme si vous “branchiez” une base de données documentaire à un modèle de langage (LLM).
Si vous vous souvenez des débuts de ChatGPT, vous lui posiez une question et il vous répondait à partir de ses “connaissances”, c’est-à-dire de milliards de paramètres. Comme un LLM ne fait que prédire la séquence de mots la plus probable, il fallait espérer qu’il ait rencontré le sujet lors de son apprentissage. ChatGPT n’avait pas accès à Internet, et si vous lui demandiez de citer des sources comme un texte de loi, il pouvait s’y plier, mais avec un fort risque d’hallucination et de toute manière l’incapacité à restituer mot pour mot le texte original. C’est normal : quand vous discutez avec un LLM, vous discutez avec une grosse machine à prédire du texte, pas une base de données.
Le RAG change cela en donnant au LLM un accès à une base de données documentaire. Le modèle peut alors récupérer des informations pertinentes, combiner plusieurs sources, puis générer une réponse plus construite, accompagnée de références précises.
Dans sa forme la plus simple, le RAG suit cette chaîne : on transforme la question, on récupère des extraits pertinents, puis le LLM répond en s’appuyant dessus.
La base de données documentaire
L’état de l’art consiste à stocker les données dans une base de données vectorielle : c’est une façon à la fois de compresser l’information et de faire des recherches par proximité sémantique. C’est la même logique que celle utilisée pour encoder du texte en vecteurs et représenter des concepts dans des espaces multidimensionnels.
Concrètement, on découpe les documents en morceaux (chunks), puis on encode ces morceaux en vecteurs pour les stocker dans la base. On peut ensuite interroger cette base avec des requêtes comme “nombre d’ETP minimum en petite crèche”. Ces requêtes sont elles aussi encodées en vecteurs et comparées à ceux présents dans la base pour retrouver les correspondances les plus proches. Les correspondances sont ensuite décodées et restituées à l’utilisateur.
En pratique, c’est souvent plus complexe : on peut aussi utiliser des bases traditionnelles contenant le texte intégral en clair, pour améliorer la précision ou faciliter certaines vérifications.
50 nuances de RAG
Dans sa forme minimale, le RAG enchaîne deux étapes :
- récupération des documents pertinents depuis la base vectorielle
- génération d’une réponse à partir des documents récupérés
C’est simple et rapide, mais pas toujours suffisant. Si la requête est complexe, par exemple “lequel de mes établissements n’a pas atteint les jours conventionnels minimum de formation pour l’année dernière”, une simple recherche sémantique peut échouer. Il faut alors aller chercher à la fois des règles réglementaires et des données métier internes, souvent stockées dans des bases distinctes.
On peut alors raffiner le modèle avec une étape d’interprétation de la question par un LLM, qui connaît les sources disponibles et orchestre des requêtes adaptées avant la génération finale.
Dès qu’une question nécessite plusieurs référentiels, on passe d’un RAG linéaire à un RAG orchestré.
À cela s’ajoutent les métadonnées associées aux chunks, les calculs, les appels à des API externes, etc. La complexité d’un RAG réside donc dans les compromis entre précision, temps de réponse et coût. On ne parle alors même plus de RAG mais d‘“Agentic Search” : c’est l’agent qui est au cœur du système, qui élabore une stratégie de recherche, et plus une simple étape de mise en forme des données récupérées.
Un garde-fou important : si l’information n’est pas trouvée dans les sources autorisées, le système doit savoir répondre “je ne sais pas” plutôt que d’inventer.
RAG et recherche Internet
Maintenant que les LLM peuvent faire des recherches web, à quoi sert le RAG ?
Si votre question porte sur des données publiques et faciles d’accès, effectivement il n’est pas toujours utile de reconstruire ces informations dans votre propre base, le LLM peut y accéder facilement par une recherche internet. En revanche, le RAG reste pertinent si vous avez des besoins spécifiques :
- informations privées qui ne doivent pas être exposées sur Internet
- information retravaillée dans un format métier (fiches pratiques, procédures internes)
- latence plus faible
- réduction des coûts en guidant un modèle plus léger avec un contexte déjà préparé
Un exemple avec la réglementation sur les crèches
Prenons l’exemple d’un juriste débutant à qui l’on demande les changements impliqués par le passage d’une crèche de 18 berceaux à 30 berceaux. Avec un système de RAG, il peut interroger des sources issues du Code de la sécurité sociale, des arrêtés sur les surfaces réglementaires, de la réglementation des établissements recevant du public (ERP), de la convention collective de la petite enfance, etc. Il peut aussi interroger les caractéristiques de l’établissement existant dans le CRM interne (ETP, surface, etc.). Il obtient ainsi une réponse unifiée avec des sources vérifiées.
Concrètement, ces bases de données sont construites en ajustant la taille des morceaux de texte et les métadonnées associées. Pour un code réglementaire, on peut découper article par article ; pour une annexe longue, on découpe plutôt en paragraphes de taille homogène.
Ce type d’orchestration permet une réponse unifiée, traçable et exploitable opérationnellement.
L’application traite la requête de l’utilisateur, orchestre les appels aux bases de données et aux LLM, puis restitue la réponse dans une interface de chat enrichie par l’accès aux documents. Ce programme peut s’exécuter sur les serveurs de l’entreprise (avec éventuellement un LLM externe pour la génération) ou entièrement dans le cloud, avec des solutions intégrées comme LlamaIndex ou Document AI de Mistral.
L’utilisateur peut maintenant dialoguer avec un assistant qui cite précisèment ses sources :

Interface de chat : l’assistant répond en citant ses sources.
Et comme le système peut restituer les documents de la base de données vectorielle, l’utilisateur peut facilement consulter le texte original pour renforcer sa confiance dans la réponse du LLM. C’est en tout cas le choix fait par votre serviteur pour répondre à un besoin précis, mais les possibilités sont infinies : rediriger vers le wiki interne / Notion / fichier pdf dans le Drive, etc.
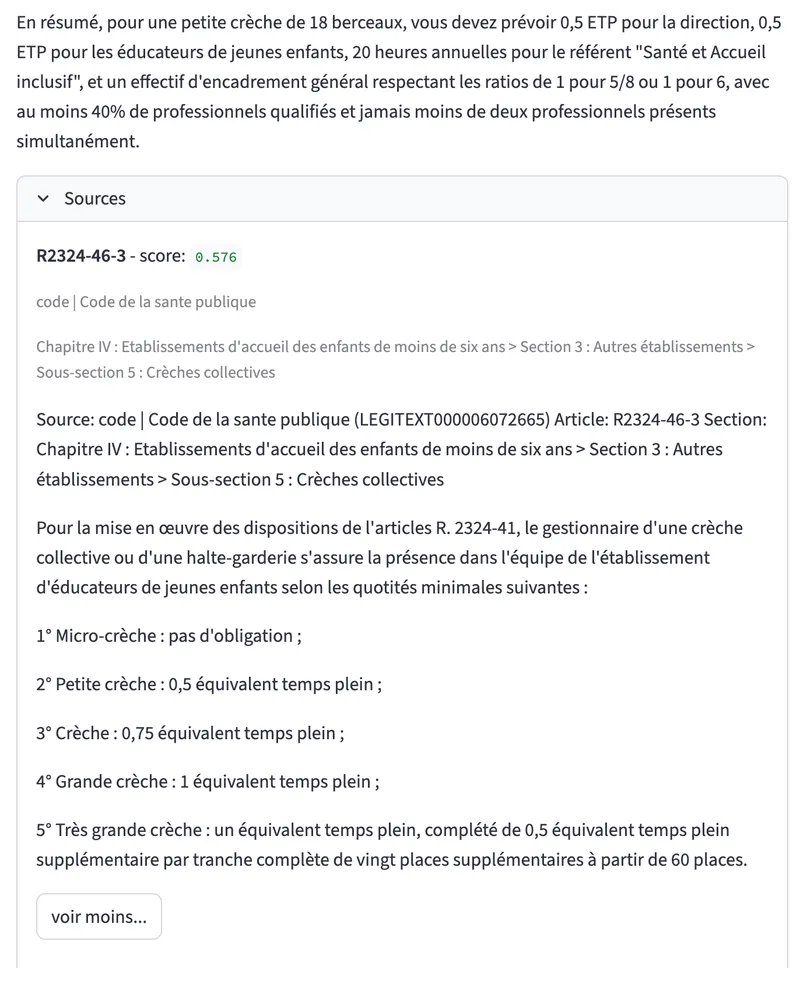
Texte intégral des articles consultable en dessous de la réponse de l’assistant.
Vous avez un projet ? Parlons-en !
Ça vous intéresse ? Contactez-moi pour discuter de vos besoins et voir si un RAG peut vous aider à améliorer votre produit ou service. Au plaisir d’échanger !